[Python][TIL] 데이터 분석에 활용 - numpy & pandas
🔔 numpy 에 대해서 알아보자
#️⃣ numpy import
import numpy as np
#️⃣ 1차원 배열
d1 이라는 1차원 배열이 있다고 할 때
d1 = np.array([1,2,3,4])
차원 dimension 은 d1.ndim 으로, 행렬 shape 은 d1.shape 로 확인할 수 있다
print('dim = ' +str(d1.ndim), 'shape = '+str(d1.shape))
d1 이라는 배열을 다음과 같이도 표현할 수 있다. ➡ arange(1,5)
d1_1 = np.array(np.arange(1,5))
#️⃣ 2차원 배열
2차원 d2 배열은 다음과 같이 나타낼 수 있다. 대괄호 안에 있는 배열 요소들이 하나의 행에 들어간다.
d2 = np.array([[1,2,3,4],
[5,6,7,8]])
dimension과 shape을 구해보면 다음과 같다. ➡ 2차원, 2행 4열
print('dim = '+str(d2.ndim), 'shape = '+str(d2.shape))
d2 라는 배열은 다음과 같이도 표현할 수 있다.
d2_1 = np.array([np.arange(1,5),
np.arange(5,9)])
#️⃣ 3차원 배열
다음과 같이 2차원 배열 두 개를 합친 것처럼 표현해서 3차원 배열을 만들 수 있다.
d3 = np.array([[[1,2,3],[4,5,6],[7,8,9],[10,11,12]],
[[21,22,23],[24,25,26],[27,28,29],[30,31,32]]])

dimension 과 shape 을 구해보면 다음과 같다.
print('dim = '+str(d3.ndim), 'shape = '+str(d3.shape))
d3 배열은 다음과 같이도 구할 수 있다.
d3_1 =np.array([[np.arange(1,4),np.arange(4,7),np.arange(7,10),np.arange(10,13)],
[np.arange(21,24),np.arange(24,27),np.arange(27,30),np.arange(30,33)]])

🔔 pandas 에 대해서 알아보자
#️⃣ pandas import
import pandas as pd
#️⃣ Series 객체
- 일차원 배열과 달리 값뿐 아니라 각 값에 연결된 인덱스 값도 동시에 저장
1. List 로 Series 생성
다음과 같은 list 가 있다.
data = ['2017', '2018', '2019', '2020']
Series 로 생성시 각 값에 연결된 인덱스가 함께 변수에 저장된다.
se = pd.Series(data)
일반 list 와 Series 는 출력되는 값이 다음과 같이 다르다.

2. 인덱스명 변경
다음과 같이 index 명을 수정할 수도 있다.
se = pd.Series(data, index = ['a', 'b', 'c', 'd'])
2. Dictionary 로 Series 생성
Series는 dictionary와 생김새가 벌써 유사하다.
다음과 같은 딕셔너리가 있다.
dic_data = {'kim':35000, 'e':60000, 'nok':40000}
Dictionary로 Series 생성은 다음과 같이 한다.
con_dictose = pd.Series(dic_data)
원래 딕셔너리 변수와 Series로 생성된 변수는 다음과 같이 출력값이 다르다.

2. 인덱스명 변경
이것도 index 명을 마음대로 수정할 수 있다.
con_dictose.index = ['A', 'B', 'C']
#️⃣ Dataframe 객체
- pandas의 기본 자료구조로, row와 column의 인덱스명이 있다.
- Series를 붙여 만든 data table
- MS Office의 엑셀 프로그램과 연동이 쉽다
1. Dataframe 생성
다음과 같은 딕셔너리 변수가 있다.
data = {'name':['Lee', 'Hwang', 'Kim', 'Choi'],
'score':[100, 95, 80, 85],
'grade':['A', 'A', 'B', 'B']
}
dataframe 을 생성
df = pd.DataFrame(data)
2. 컬럼 순서 변경
다음과 같이 name, grade, score 순서로 컬럼의 순서도 수정할 수 있다.
df = pd.DataFrame(data, columns=['name', 'grade', 'score'])
3. 인덱스명 변경
인덱스명도 다음과 같이 두 가지 명령어로 수정할 수 있다.
방법 1)
df = pd.DataFrame(data, index = ['Lee', 'Hwang', 'Kim', 'Choi'])
방법 2)
df.index = ['이', '황', '김', '최']
4. 인덱스 기준 정렬
오름차순 정렬
df.sort_index(axis=0)

5. 컬럼 기준 정렬
오름차순 정렬
df.sort_values(by=['score'])

내림차순 정렬
df.sort_values(by=['score'], ascending=False)

컬럼 두 개 기준 오름차순 정렬
df.sort_values(by=['grade','score'])grade 컬럼 기준으로는 오름차순, score 컬럼 기준으로는 내림차순으로 정렬
df.sort_values(by=['grade','score'], ascending=[True, False])

6. 그룹화 (SQL의 group by 개념)
다음과 같은 list가 있다.
student_list = [{'name': 'John', 'major': "Computer Science", 'sex':"male"},
{'name': 'Nate', 'major': "Computer Science", 'sex':"male"},
{'name': 'Abraham', 'major': "Physics", 'sex':"male"},
{'name': 'Brian', 'major': "Psychology", 'sex':"male"},
{'name': 'Janny', 'major': "Economics", 'sex':"female"},
{'name': 'Yuna', 'major': "Economics", 'sex':"female"},
{'name': 'Jeniffer', 'major': "Computer Science",'sex': "female"},
{'name': 'Edward', 'major': "Computer Science",'sex': "male"},
{'name': 'Zara', 'major': "Psychology", 'sex':"female"},
{'name': 'Wendy', 'major': "Economics", 'sex':"female"},
{'name': 'Sera', 'major': "Psychology", 'sex':"female"}]
위의 list로 dataframe 생성
df = pd.DataFrame(student_list, columns = ['name', 'major', 'sex'])
major 라는 컬럼을 기준으로 그룹화하면 다음과 같다.
groupby_major = df.groupby('major')data type은 다음과 같다. ➡ pandas.core.groupby.groupby.DataFrameGroupBy
type(groupby_major)
몇 번째 행들이 그룹으로 묶였는지 다음과 같은 명령어로 확인할 수 있다.
groupby_major.groups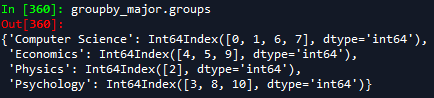
이걸 for 문을 사용하여 테이블 형식으로 출력해보면
for name, group in groupby_major:
print(name + ": " + str(len(group)))
print(group)
print()
각 그룹의 요소들의 수를 계산하는 명령어는 다음과 같다.
df_major_cnt = pd.DataFrame({'count' : groupby_major.size()}).reset_index()
#️⃣ 엑셀 파일 읽어오기
Y2018 = pd.read_excel('저장경로/엑셀 파일명.xlsx', 'Y2018')
Y2019 = pd.read_excel('저장경로/엑셀 파일명.xlsx', 'Y2019')
Y2020 = pd.read_excel('저장경로/엑셀 파일명.xlsx', 'Y2020')



1. 서로 다른 엑셀 파일 합치기 (마치 SQL의 union all과 같다)
방법1)
Y_total = pd.concat([Y2018,Y2019,Y2020], axis=0,ignore_index = True)
방법2)
2018년도에 2019년도를 합치고, 2020년도를 순서대로 합친다.
Y_total2 = Y2018.append(Y2019,ignore_index = True)
Y_total2 = Y_total2.append(Y2020,ignore_index = True)
2. 엑셀 파일로 저장하기 (csv 파일을 제공해야 할 때)
Y_total.to_csv('저장경로/엑셀 파일명.csv')

만약 header 를 지우고 싶다면
Y_total.to_csv('저장경로/엑셀 파일명.csv', header = False, index =False)

3. 이어진 특정 행 추출 (파이썬의 슬라이싱처럼)
# 첫 행부터 22행까지만 추출
a1 = Y_total[:23]
# 23행부터 46행까지 추출
a2 = Y_total[23:47]
4. 이어지지 않은 특정 행 추출
# 맨 윗줄 뽑아
b1 = Y_total.loc[0]
# 0번 4번줄 뽑아
b2 = Y_total.loc[[0,4]]
5. 필터링 (SQL의 where절에 조건 쓰는 것처럼)
d1 = Y_total[Y_total.기온 >= 35]
d2 = Y_total[Y_total.기온 <= -15]
d3 = Y_total[(Y_total.기온 >=35)&(Y_total.지면온도 >=40)]
d4 = Y_total[Y_total.일시 == '2018-01-01 01:00:00']만약 컬럼이 날짜관련이라면 다음과 같이 연도, 월, 일, 시간을 잡아놓을 수 있다.
Y_total['Year'] = Y_total['일시'].dt.year
Y_total['Month'] =Y_total['일시'].dt.month
Y_total['Day'] =Y_total['일시'].dt.day
Y_total['time'] =Y_total['일시'].dt.time
Y_total['hour'] =Y_total['일시'].dt.hour고렇게 잡아놓고 11월 3일자의 데이터들만 출력할 수 있다.
d5 = Y_total[(Y_total.Month == 11)&(Y_total.Day == 3)]
6. merge (SQL의 join처럼)
아래 두 엑셀파일은 state 컬럼이 동시에 존재한다. state 컬럼을 인덱스로 가져와 dataframe으로 저장한다.
alco = pd.read_csv("저장경로/엑셀 파일명.csv", index_col="State")
popu = pd.read_csv("저장경로/엑셀 파일명.csv", index_col="State")
state 를 기준으로 두 엑셀파일을 merge 한다.
us_mer1 = pd.merge(alco.reset_index(), popu.reset_index()).set_index("State")
7. 인터넷 주소로 엑셀 파일 가져오기
#️⃣ 그래프 형상화
matplotlib.pyplot import
# 그래프 그려주는 라이브러리
import matplotlib.pyplot as plt
# figure를 자동으로 윈도우 창으로 띄우는 명령어
%matplotlib auto
다음과 같이 x 와 y 변수에, 엑셀로 가져온 sheet 의 특정 컬럼들만 추출해서 저장한다.
x = Y_total['일시']
y1 = Y_total['기온']
y2 = Y_total['지면온도']
y3 = Y_total['풍속']
1. 그래프 형상화
plt.figure()위의 함수를 실행하면 Figure의 윈도우 창이 새롭게 생성된다.

plt.plot(x,y1*0.5)
plt.plot(x,y2)두 컬럼 값을 각각 x축, y축으로 잡고 그래프를 그리면 다음과 같이 그려질 수 있다.


2. 격자무늬
plt.grid()
3. 축이름 추가
plt.xlabel('time')
plt.ylabel('temp')